


 |
 |
||||||||||
 |
Come si fa ricerca in Internet
Ricerca libera su WebTre strumenti diversiWorld Wide Web è la risorsa Internet probabilmente più nota, e i suoi ritmi di espansione sono esponenziali. Le pagine informative immesse in rete riguardano gli argomenti più vari, e provengono da fornitori di informazione di natura assai eterogenea: dalle università alle industrie private (grandi e piccole), dai centri di ricerca ai negozi, dalle imprese editoriali ai partiti politici. Vi sono poi le numerosissime 'home page' personali del popolo di Internet. Chi svolge una ricerca in rete si trova dunque davanti un duplice problema: reperire l'informazione cercata e valutare la sua correttezza, completezza, affidabilità. Il secondo compito, assai delicato, dipende in parte dall'esperienza; un consiglio generale - una volta trovata una pagina informativa che reputiamo interessante - è quello di risalire sempre alla home page del sito che la ospita (molti siti rendono disponibile su ogni pagina un link alla home page; se così non fosse, si può provare ad 'accorciare' progressivamente l'indirizzo nella barra delle URL, salendo di livello in livello nella struttura gerarchica del sito). In questo modo potremo in genere reperire informazioni su chi ha immesso in rete quella particolare pagina, in quale contesto e a quali fini. Quanto al primo problema - quello di 'scoprire' le pagine esistenti che si occupano di un determinato argomento - una buona partenza è in genere rappresentata dagli strumenti di ricerca disponibili in rete. Cominciamo da due tipi di risorse che è bene conoscere e che, innanzitutto, occorre saper distinguere (molto spesso queste due diverse tipologie di risorse vengono mescolate e confuse, anche da parte di 'esperti' della rete): i motori di ricerca per termini e gli indici sistematici. I motori di ricerca per termini permettono di ricercare parole o combinazioni di parole in un archivio indicizzato di documenti in formato digitale. Se vogliamo ad esempio cercare le pagine che si occupano di Lewis Carroll (pseudonimo del reverendo Dodgson, l'autore di Alice nel paese delle meraviglie), potremo fornire al motore di ricerca le due parole 'Lewis' e 'Carroll'. In molti casi è possibile combinare le parole fornite utilizzando i già ricordati operatori booleani: ad esempio, una ricerca con chiave 'Lewis AND Carroll' potrebbe fornirci le pagine in cui compaiono tutti e due i nomi, aiutandoci a scremare pagine che non ci interessano. E, ancor meglio, un operatore capace di 'concatenare' i due termini ci garantirebbe di trovare solo le pagine in cui compare l'esatta stringa 'Lewis Carroll'. Attenzione: come si è già accennato a proposito della ricerca su basi dati, la sintassi corretta per utilizzare AND, OR, NOT e gli eventuali altri operatori disponibili varia da un motore di ricerca all'altro. Nella maggior parte dei casi comunque non dovremo digitare direttamente gli operatori booleani: basterà utilizzare strumenti più intuitivi, ad esempio un menu a tendina che ci permetta di specificare se ci interessano le pagine in cui compaiono tutti i termini cercati o almeno uno di essi. La ricerca attraverso un motore di ricerca per termini è molto comoda nel caso di nomi propri, o nel caso in cui le informazioni che vogliamo trovare si lascino caratterizzare attraverso termini molto specifici. Occorre tuttavia tenere presente che si tratta di una ricerca meccanica: il programma utilizzato non farà altro che cercare i termini da noi forniti all'interno di un immenso indice alfabetico in suo possesso - indice tenuto aggiornato da un 'demone' software che si muove continuamente lungo la rete, seguendo ogni link incontrato e indicizzando tutte le pagine percorse - e fornirci le corrispondenze trovate. L'intelligenza della ricerca dipende dunque in gran parte dalla scelta delle parole usate come parametri, anche se come vedremo quasi tutti i motori di ricerca hanno la capacità di 'pesare' i risultati in base a elementi quali il numero di occorrenze della parola, l'occorrenza in zone significative del documento come i titoli o i link, e così via. Ciò significa che se abbiamo scelto bene i nostri termini di ricerca, riceveremo un elenco di pagine che avrà alte possibilità di iniziare da quelle per noi più significative. Ma se ad esempio avremo effettuato una ricerca con chiave 'Lewis Carroll', non troveremo mai le pagine nelle quali compare solo il nome di Dodgson. Va ricordato, inoltre, che, per quanto estesa, la base di indicizzazione di un motore di ricerca per termini copre solo una parte delle pagine realmente disponibili in rete. I dati effettivi sono molto difficili da stimare. Si calcola che le pagine Web esistenti fossero circa 50 milioni nel novembre 1995, circa 320 milioni nel dicembre 1997, circa 800 milioni nel febbraio 1999... ma più ci si avvicina a oggi, più queste stime sono incerte. Google indicizzava circa un miliardo e mezzo di pagine a metà 2002, e a maggio 2003 dichiara di indicizzare oltre tre miliardi di pagine Web. È probabile che nessun motore di ricerca arrivi a coprire più del 30-35% del numero complessivo di pagine in rete: possiamo dunque pensare che, a metà 2003, il numero complessivo di pagine Web sia a grandi linee compreso fra i 7 e i 10 miliardi. E ricordate che il Web non è fatto solo di pagine HTML: ci sono documenti di ogni genere, immagini, file audio... È facile capire, dunque, che i risultati di una ricerca in rete, per quanto accurata e ben condotta, non vanno mai considerati completi o definitivi. E che la stessa ricerca, svolta in momenti diversi o utilizzando strumenti diversi, potrà fornire (anzi, fornirà quasi sempre) risultati diversi. Al contrario della ricerca alfabetica, la ricerca sistematica avviene su cataloghi ragionati di risorse, suddivisi per settori e organizzati gerarchicamente; per questi cataloghi, o indici sistematici, è spesso usato il nome inglese directory. In genere la base dati è assai più ristretta (saremo dunque ancor meno sicuri di quanto non accada nel caso dei motori di ricerca di trovare direttamente tutte, o anche solo la maggioranza delle pagine che ci interessano), ma la valutazione della pertinenza o meno di una determinata informazione non sarà più meccanica, bensì risultato di una decisione umana, e l'informazione stessa sarà inserita all'interno di una struttura di classificazione. Un'altra differenza rilevante è che il motore di ricerca per termini indicizza (e dunque restituisce) singole pagine - quelle nelle quali compare il termine cercato - , mentre l'indice sistematico indicizza interi siti, anche se ovviamente l'accesso al sito avviene anch'esso attraverso una pagina: la sua pagina iniziale o home page. Naturalmente, nel caso di un indice sistematico i principi utilizzati per costruire l'impianto classificatorio della banca dati sono fondamentali. Un catalogo ragionato di questo tipo si basa in genere su una sorta di 'albero delle scienze', da percorrere partendo da categorizzazioni più generali per arrivare via via a categorizzazioni più specifiche. Ed è importante che le categorie siano sensate, e il percorso di 'discesa al particolare' avvenga attraverso itinerari intuitivi e coerenti: due compiti, come vedremo, tutt'altro che facili. La differenza tra motori di ricerca per termini e indici sistematici è sostanziale, nonostante sia invalso l'uso - concettualmente fuorviante - di utilizzare per entrambi il termine 'motore di ricerca', e la confusione sia accresciuta dal fatto che, come vedremo, molti indici sistematici, come Yahoo!, permettono l'accesso anche a un motore di ricerca per termini, e viceversa. L'esame dettagliato di alcune fra le risorse disponibili per la ricerca su World Wide Web ci aiuterà a comprendere meglio questi problemi. Sottolineiamo però fin d'ora l'importanza di un terzo tipo di ricerca, del quale è assai più difficile fornire un inquadramento generale: la navigazione libera attraverso pagine di segnalazioni di risorse specifiche. È infatti quasi una norma di 'netiquette' che chi rende disponibili informazioni su un determinato argomento, fornisca anche una lista di link alle principali altre risorse esistenti in rete al riguardo. Questo tipo di liste ragionate va naturalmente esso stesso cercato e trovato, cosa che in genere viene fatta usando indici alfabetici o cataloghi sistematici di risorse secondo le modalità sopra delineate. Una volta però che abbiamo individuato una di queste pagine-miniera di link specifici, potrà essere produttivo proseguire la nostra ricerca attraverso di essa. Le risorse in tal modo segnalate presentano infatti due importanti caratteristiche: sono state scelte in maniera esplicita e ragionata, e la scelta è presumibilmente opera di una persona che conosce bene il settore in questione. Abbiamo trovato comodo caratterizzare con l'espressione navigazione orizzontale questa terza modalità di ricerca su Web. Gli indici sistematiciIl primo strumento di cui ci occuperemo è rappresentato dai cataloghi sistematici e ragionati di risorse; come si è accennato, spesso questi cataloghi sono chiamati col termine inglese directory. Il modello adottato ricorda l'arbor scientiae di derivazione medievale e rinascimentale, largamente usato anche in ambito enciclopedico e bibliotecario come alternativa alla organizzazione alfabetica. Naturalmente in questo caso la scelta dei rapporti gerarchici e l'importanza relativa attribuita ai vari settori dello scibile hanno finito inevitabilmente per essere influenzati (e lo erano ancor più nei primi anni di vita della rete) dalla rilevanza che gli strumenti informatici e telematici hanno in ogni singolo settore. Così, ad esempio, fra i 'rami' principali dell'albero compaiono discipline come l'informatica e la telematica, mentre discipline come la teologia e la filosofia, che avevano un ruolo preminente negli alberi delle scienze di qualche secolo fa, sono in genere relegate a sottocategorie. I modelli alla base di queste classificazioni, che nascono quasi tutte nel mondo statunitense e tradiscono spesso un certo indebitamento verso la tradizione del positivismo anglosassone, sarebbero un argomento interessante per una ricerca universitaria. In una risorsa di questo tipo, elemento fondamentale è evidentemente la scelta delle suddivisioni interne delle varie discipline: ad esempio, le informazioni relative alla musica delle popolazioni primitive andranno catalogate sotto la voce 'antropologia' (presumibilmente una sottovoce del settore 'scienze umane') o sotto la voce 'musica'? Per fortuna la struttura ipertestuale di World Wide Web permette di superare problemi di questo tipo, che avevano angustiato generazioni e generazioni di enciclopedisti e bibliotecari 'lineari'. Nulla impedisce, infatti, di classificare una stessa sottocategoria sotto più categorie diverse (ed eventualmente a 'livelli' diversi dell'albero). Non vi sarà alcun bisogno, per farlo, di duplicare l'informazione: basterà duplicare i link. Visto da un punto di vista lievemente più tecnico, questo significa che gli indici sistematici di risorse sono strutturalmente più simili a grafi complessi che ad alberi: a uno stesso nodo si può arrivare attraverso percorsi alternativi, tutti egualmente validi. Dal punto di vista dell'utente, invece, ciò comporta semplicemente che - a meno di non andarla a cercare sotto categorie palesemente innaturali - trovare una determinata risorsa informativa sarà di norma assai facile: se ben compilato, l'indice sembrerà 'adattarsi' alle nostre scelte di categorizzazione. Quanto abbiamo detto finora può sembrare un po' teorico; vediamo allora di capire meglio come funzionano questi strumenti, analizzandone più da vicino i due esempi più importanti; Yahoo! e Open Directory.
Yahoo!Yahoo! è nato nell'informaticamente lontanissimo aprile 1994, quando David Filo e Jerry Yang, studenti di ingegneria elettronica all'Università di Stanford, iniziarono a creare pagine riassuntive con link ai siti Internet di loro interesse. Nel corso del 1994, Yahoo! (a proposito: la sigla ricorda naturalmente il grido di gioia che si suppone seguire all'individuazione dell'informazione cercata, anche se è ufficialmente sciolta dal curioso acronimo 'Yet Another Hierarchical Officious Oracle') si trasformò progressivamente in un vero e proprio database, ricco di migliaia di pagine indicizzate. All'inizio del 1995 Mark Andreessen, cofondatore della Netscape, percepì l'interesse dello strumento creato da Filo e Yang, e si offrì di contribuire alla trasformazione dell'iniziativa in una impresa commerciale. Adesso Yahoo! è una impresa privata, quotata in borsa, finanziata fra l'altro attraverso le 'inserzioni' pubblicitarie accolte a rotazione nelle sue pagine, e sopravvissuta piuttosto bene alla crisi della net economy. La sua funzione di indice sistematico di risorse è stata progressivamente affiancata da una miriade di funzionalità aggiuntive: ad esempio, Yahoo! ospita uno dei maggiori servizi per la gestione via web di indirizzi e-mail gratuiti (Yahoo! Mail) e una delle maggiori raccolte di pagine personali (Yahoo! GeoCities), e abbiamo già ricordato sia il suo servizio per la gestione di comunità web (Yahoo! Groups) sia il suo servizio di instant messaging (Yahoo! Messenger), collegato a una delle chat più vaste, articolate e frequentate della rete (Yahoo! Chat). In questa sede, ci interessa però la funzionalità originaria e tuttora fondamentale del servizio: quella appunto di indice sistematico o directory. Utilizzarla è assai semplice. Si può partire dall'indirizzo principale di Yahoo! (la URL è naturalmente http://www.yahoo.com/), ma suggeriamo - quando è proprio la directory che ci interessa - di partire invece dall'indirizzo http://dir.yahoo.com/, che offre un'interfaccia assai meno affollata e dispersiva e (come vedremo) rende assai più chiara la funzione del campo 'Search'. La pagina che troverete è quella rappresentata nella figura seguente. L'indice è organizzato in categorie e sottocategorie: le voci in grassetto sono le categorie principali, quelle in carattere più piccolo sono alcune fra le loro sottocategorie. Supponiamo di ricercare informazioni sulle agenzie di traduzione raggiungibili attraverso Internet (esistono ormai molti servizi di questo tipo, nei quali la possibilità di scambio veloce e senza limiti geografici di testi costituisce un valore aggiunto notevolissimo). Presumibilmente, una buona categoria di partenza è quella 'Business and Economy'. Se seguiamo il collegamento disponibile, troveremo un'ampia lista di sottocategorie. Cerchiamo un'agenzia professionale, che prevedibilmente offre i propri servizi in primo luogo alle aziende, quindi proveremo a partire dalla sottocategoria 'Business to Business'. Fra le moltissime suddivisioni ulteriori di questa categoria, troveremo quella che fa al caso nostro: 'Translation Services'. Una lista che al momento in cui scrivevamo Internet '96 comprendeva i link alle pagine in rete di 168 diverse agenzie di traduzione, diventate ben 759 nel momento in cui scrivevamo Internet 2000, e - in barba alla crisi della new economy - ulteriormente cresciute fino a 971 nell'aprile 2003.
Il percorso che abbiamo seguito potrebbe risultare per qualcuno - non del tutto a torto - poco naturale. Per fortuna, però, saremmo arrivati allo stesso risultato anche seguendo itinerari diversi: ad esempio, saremmo potuti partire dalla categoria 'Social Science', passando alla sottocategoria 'Linguistics and Human Languages', nella quale è pure presente un link alla voce 'Translation Services'. Le categorizzazioni di Yahoo! - come quelle di qualsiasi altro indice sistematico dello stesso genere - sono spesso altamente discutibili03, ma la moltiplicazione delle strade di accesso rende molto difficile perdersi completamente. Yahoo! permette inoltre una ricerca per parole chiave che - a patto di saperne interpretare i risultati - si rivela spesso il sistema più rapido per individuare la categoria cercata. Nel nostro caso, sarebbe bastato inserire il termine 'translation' nella casella 'Search' presente sulla pagina http://dir.yahoo.com/, controllare che sia selezionata l'opzione di ricerca relativa alla directory e non al web, e avviare la ricerca.
Attenzione: proprio perché abbiamo selezionato l'opzione di ricerca su directory, e a differenza di quanto avviene nel caso dei motori di ricerca per termini (dei quali ci occuperemo tra breve), questa ricerca non riguarda il testo integrale delle pagine presenti su Web, ma solo il database interno di Yahoo!. Come potete vedere dalla figura 65, i risultati sono suddivisi in due sezioni: quella delle 'Related directory categories' e quella dei 'Directory results'. La prima elenca tutte le categorie dell'albero classificatorio di Yahoo! in cui è presente il termine 'translation', la seconda invece tutti i siti catalogati da Yahoo! nel cui nome o nella cui descrizione è presente il termine 'translation'. A noi in questo caso interessano le categorie: con un click su 'More...' nell'ambito delle 'Related directory categories' arriveremo a un elenco di categorie che comprende quella ('Translation Services') che cercavamo. Questa funzione permette dunque in genere di individuare, più che le singole risorse informative, le categorie che ci interessano.
Attenzione: se invece di compiere la nostra ricerca dal modulo 'Search' presente nella pagina http://dir.yahoo.com/, avendo selezionato l'opzione di ricerca su directory, avessimo compiuto la stessa ricerca selezionando l'opzione di ricerca su Web o partendo dalla home page generale di Yahoo! (http://www.yahoo.com/), saremmo arrivati a un risultato del tutto diverso: non più 8 categorie o 2.088 siti presenti nell'indice sistematico di Yahoo!, ma (nel momento in cui scriviamo) ben 8.150.000 pagine Web in cui compare il termine 'translation'. Questo tipo di ricerca, infatti, fa 'cambiare pelle' a Yahoo!, che si trasforma da indice sistematico in motore di ricerca per termini. Ovviamente, se cercavamo una agenzia di traduzioni, aver a che fare con oltre otto milioni di pagine Web è piuttosto dispersivo: l'uso della chiave di ricerca 'translation', che rappresentava una buona strategia all'interno dell'indice sistematico, si rivela del tutto inadatto ai nostri scopi se passiamo a utilizzare un motore di ricerca che indicizza le singole pagine Web. Purtroppo, la natura sempre più 'ibrida' di Yahoo! non semplifica il compito di distinguere fra questi due tipi di ricerca. Ma la distinzione, se vogliamo ottenere risultati utili e pertinenti, è essenziale. Anche per questo, quando svolgete una ricerca con Yahoo! tenete sempre d'occhio la barra orizzontale che si trova sopra la pagina di risultati: attraverso di essa potrete accorgervi in ogni momento se la vostra ricerca si svolge sulle pagine Web o all'interno dell'indice sistematico di Yahoo!, e passare, con un semplice click, da una ricerca all'altra. Tenete anche presente che, se state usando Yahoo! come motore di ricerca per termini, potrete passare alla ricerca per categorie anche utilizzando la freccetta rossa presente sotto alcuni dei risultati: la presenza di tale freccia segnala che il sito al quale appartiene la pagina in questione è presente anche nell'indice sistematico di Yahoo! directory, e indica la relativa categoria. Di Yahoo! sono disponibili versioni specifiche per diversi paesi, fra i quali l'Italia. La versione italiana di Yahoo! è all'indirizzo http://www.yahoo.it/. Attenzione, però: non si tratta di una traduzione italiana dell'intero indice disponibile nella versione anglosassone, ma di un indice 'mirato' relativo alle risorse in italiano: il nostro consiglio è di usarlo non come sostituto del sito originale statunitense (assai più ampio e completo), ma come utile complemento nel caso di ricerche che riguardino in tutto o in parte il nostro paese. Open DirectorySe Yahoo! è sicuramente l'indice sistematico più noto al grande pubblico, negli ultimi anni è progressivamente cresciuto un altro, prezioso servizio di catalogazione sistematica dei siti. Si tratta di Open Directory (http://dmoz.org/), un progetto nato con una filosofia assai diversa da quella dell'impresa di Filo e Yang. Al posto del lavoro retribuito di un centinaio di redattori professionisti, Open Directory si basa sulle segnalazioni di diverse migliaia (circa 56.000 nell'aprile 2003) di volontari. Un sistema di controlli incrociati permette di verificare l'affidabilità delle segnalazioni e della loro categorizzazione. Come è facile comprendere, una risorsa con queste caratteristiche si basa largamente sullo spirito collaborativo della rete, e sull'idea della libera condivisione di conoscenze tipica del movimento dell'open software. Ciò non ha impedito tuttavia a Open Directory di diventare una realtà di tutto rispetto anche dal punto di vista commerciale. Gestita da AOL (America On Line) attraverso la Netscape Corporation04, Open Directory è infatti l'indice sistematico offerto da portali e siti di ricerca di tutto rilievo: innanzitutto Google (http://www.google.com/dirhp/), e fra gli altri America On Line, Netscape, Lycos, HotBot, Excite. L'organizzazione di Open Directory è quella, familiare, in categorie e sottocategorie. Il pulsante 'Search' in questo caso - come ci aspetteremmo - svolge la sua funzione all'interno del database di Open Directory e non sull'universo delle pagine Web. Nel momento in cui scriviamo, Open Directory cataloga quasi quattro milioni di siti, organizzati in oltre 460.000 categorie, mentre Yahoo! cataloga fra i due e i tre milioni di siti. Open Directory offre dunque una base più ampia di siti indicizzati; il 'sorpasso' di Open Directory su Yahoo! è avvenuto nell'aprile 2000: all'epoca è passato quasi inosservato, ma si è trattato di un momento importante nel confronto fra due diverse strategie per la costruzione di risorse di indicizzazione su Web. Tuttavia, la maggiore eterogeneità delle scelte operate da una base così vasta di collaboratori si fa talvolta sentire: per coordinare al meglio il loro lavoro occorrerebbe forse un nucleo di 'professionisti' più ampio e preparato di quello attualmente disponibile. Open Directory dispone di sezioni nazionali, una delle quali in italiano: il sistema più semplice per arrivarvi è partire dal sito italiano di Google (http://www.google.it/), selezionare la scheda 'Directory' e, al suo interno, la voce 'World - Italiano'. Altri servizi di catalogazione sistematicaYahoo! e Open Directory non sono gli unici servizi di catalogazione sistematica delle risorse disponibili su Internet, ma come si accennava sono al momento quelli di gran lunga più completi. Una certa diffusione ha anche la directory di Looksmart (l'indirizzo è http://www.looksmart.com/; è tuttavia preferibile utilizzare gli indici di Looksmart attraverso i siti dei suoi partner: il sito della società infatti non è organizzato per una comoda consultazione), costruita con un criterio misto: in parte (per le aziende) a pagamento, in parte (per i siti non commerciali) attraverso un servizio di autosegnalazione gratuito. L'indice di Looksmart è utilizzato nella sezione 'directory' di Altavista (http://www.altavista.com/dir/default/) e di Microsoft Network (http://search.msn.com/). Una segnalazione merita About (http://www.about.com/): una directory organizzata in circa 700 aree tematiche, ciascuna delle quali affidata a un volontario esperto ('guida'). I siti segnalati sono molto meno numerosi di quelli compresi negli altri indici sistematici dei quali abbiamo parlato, e la griglia delle categorie è più spartana, ma le risorse sono commentate in maniera assai più analitica e accompagnate da articoli di introduzione e orientamento che possono rivelarsi talvolta preziosi. Segnaliamo anche Infogrid, che unisce in maniera abbastanza efficace le funzioni di Web directory e di metamotore di ricerca (una tipologia di strumenti della quale parleremo fra breve). L'indirizzo è http://www.infogrid.com/. Infine, vi suggeriamo un sito che non è un vero e proprio indice sistematico generalista ma piuttosto un elenco di risorse nel prezioso settore degli strumenti di 'reference': dizionari, vocabolari, enciclopedie, atlanti e servizi di mappe, e così via (inclusi gli stessi indici sistematici del Web). L'indirizzo è http://www.reference.com/. Su Web esistono naturalmente molti altri indici sistematici, talvolta più ampiamente commentati di quelli di Yahoo! e Open Directory o costruiti attraverso griglie classificatorie e con criteri diversi. Si tratta comunque di siti assai meno completi e sistematici, e spesso decisamente orientati verso il volto commerciale della rete. Un buon punto di partenza per esplorarli è la pagina dedicata all'argomento da Open Directory: l'indirizzo è http://dmoz.org/Computers/Internet/Searching/Directories/. Un discorso a parte meritano gli indici in italiano, utili per chi desidera evitare eccessive acrobazie linguistiche con le categorizzazioni inglesi, ma soprattutto per chi desidera effettuare ricerche limitate allo specifico del nostro paese. Tenete presente, però, che la completezza è in genere molto inferiore a quella dei corrispondenti siti in inglese, talvolta anche per quanto riguarda le informazioni relative agli stessi siti italiani. Delle versioni italiane di Yahoo! e Open Directory abbiamo già detto. Fra gli altri servizi vanno segnalati in primo luogo Virgilio, che offre una scelta informativa ricca anche di articoli e suggerimenti (la URL è ovviamente http://www.virgilio.it/), e Arianna, ora di proprietà di Libero, che permette ricerche sia sul proprio indice di siti italiani, sia sui principali motori internazionali (http://arianna.libero.it/). L'indice sistematico italiano che preferiamo è tuttavia SuperEva (http://www.supereva.it/); la directory è all'indirizzo http://dir.supereva.it/, e integra le segnalazioni di un'altra web directory italiana, quella di 100Links (http://100links.supereva.it/). Il sito è nato nel dicembre 1999 ed è realizzato dalla società Dada, che un po' sul già citato modello di About si affida a una nutrita schiera di guide per realizzare una serie di schede tematiche dedicate alla segnalazione di risorse Web. L'affidabilità delle segnalazioni varia da guida a guida, ma nel complesso si tratta di una risorsa ricca e articolata. Ricordiamo infine Il Trovatore (http://www.iltrovatore.it/), anche se è assai fastidiosa la finestra pop-up che si apre a ogni accesso per chiederci se ne vogliamo fare la pagina iniziale delle nostre navigazioni, Godado (http://www.godado.it/), dichiaratamente orientato al marketing e dunque per certi versi più vicino al modello Pagine gialle che a un vero e proprio indice sistematico, e ABCItaly, che dichiara un catalogo di 80.000 siti italiani (organizzati in verità in maniera piuttosto caotica; l'indirizzo è http://www.abcitaly.com/). I motori di ricercaI motori di ricerca per terminiDagli indici sistematici di risorse, passiamo ora alla seconda grande categoria di strumenti di ricerca su Web: i motori di ricerca per termini. Come si è accennato in precedenza, in questi casi la ricerca avviene indicando una parola, o una combinazione di parole, che consideriamo associata al tipo di informazione che vogliamo reperire, e insieme abbastanza specifica da non produrre una quantità eccessiva di risultati non pertinenti. Questo evidentemente può avvenire solo se abbiamo un'idea sufficientemente chiara di quello che stiamo cercando, e se l'ambito della nostra ricerca può essere associato in maniera ragionevolmente immediata a un termine, o a un piccolo insieme di termini. Il caso tipico è quello in cui la nostra ricerca riguarda una persona. Scegliamo come esempio una ricerca di informazioni sulla scrittrice Jane Austen, e vediamo come condurla utilizzando quello che negli ultimi anni si è decisamente imposto come il miglior motore di ricerca per termini disponibile su Internet: Google. Fondato nel settembre 1998 da Larry Page e Sergey Brin, Google è diventato in pochissimi anni il motore di ricerca su Web, tanto da far nascere nel mondo anglosassone il neologismo to google, che indica appunto l'attività di svolgere una ricerca in rete utilizzando l'omonimo servizio. A fine agosto 2003 Google dichiara di indicizzare oltre tre miliardi e trecento milioni di pagine Web (o meglio, documenti accessibili su Web: Google infatti indicizza, oltre alle pagine HTML, anche diversi altri tipi di documenti, a condizione che essi siano disponibili all'interno di un sito Web aperto al pubblico; fra gli altri, file PDF, documenti Word, presentazioni PowerPoint), ha più di 800 dipendenti, e risponde a oltre duecento milioni di richieste al giorno. Il singolare nome del sito è un gioco di parole basato sulla parola 'googol', inventata da Milton Sitotta, nipote del matematico Edward Kasner, per riferirsi al numero rappresentato da un '1' seguito da cento '0': simbolo dunque dell'enorme quantità di informazione che il motore di ricerca si propone di dominare. L'indirizzo di Google è http://www.google.com/; il sito è in grado di interpretare le impostazioni del browser relative alle lingue preferite (in Internet Explorer è possibile verificare queste impostazioni attraverso il pulsante 'Lingue' nelle 'Opzioni Internet' raggiungibili attraverso il menu 'Strumenti'; in Netscape esse sono raggiungibili attraverso la voce 'Preferenze' del menu 'Modifica', all'interno della sottocartella 'Lingue' della cartella 'Navigator'), presentandosi automaticamente con l'interfaccia nella lingua preferita dall'utente. La traduzione riguarda solo l'interfaccia, mentre il database sul quale viene svolta la ricerca è comunque lo stesso. Al momento in cui scriviamo, l'interfaccia inglese offre alcune funzioni non presenti nelle interfacce in altre lingue (ad esempio la ricerca su notizie): è bene dunque tener presente che, anche se al primo accesso il sito si presenta in italiano, l'interfaccia inglese è sempre raggiungibile attraverso il link 'Google in English'. L'interfaccia italiana di Google è raggiungibile anche all'indirizzo http://www.google.it/, mentre alla pagina http://www.google.it/language_tools?hl=it potete scegliere l'interfaccia preferita fra una novantina di lingue diverse, inclusi il latino, l'esperanto e addirittura (per gli amanti di Star Trek) il klingon.
La ricerca attraverso Google è possibile in due modalità: la ricerca semplice e quella avanzata. Nella modalità di ricerca semplice, la linguetta 'Web' ci conferma che la nostra ricerca si svolgerà sulla base dati costituita dalle pagine Web (ci occuperemo in seguito della ricerca di immagini, o su newsgroup, mentre la linguetta 'Directory' ci porta al già citato indice sistematico che Google mutua da Open Directory). Per inserire i termini da cercare, è a nostra disposizione un semplicissimo modulo composto da un unico campo. Se inseriamo più di un termine la ricerca avviene in 'AND', e restituisce dunque le pagine in cui compaiono tutti i termini inseriti. Per avviare la ricerca, una volta inseriti i termini da ricercare basta premere il pulsante 'Cerca con Google' ('Google Search' nell'interfaccia inglese). Il pulsante 'Mi sento fortunato' ('I'm Feeling Lucky') è una divertente peculiarità di Google: se lo premiamo al posto del pulsante 'Cerca con Google', anziché arrivare a una lista di pagine Web che soddisfano i nostri criteri di ricerca salteremo direttamente alla prima di tali pagine. La presenza di questa opzione vuole richiamare quello che è stato fin dalla nascita uno dei vanti principali di Google: l'algoritmo di ordinamento dei risultati. Tale algoritmo, in continua evoluzione e via via sempre più sofisticato ed efficace, ha la funzione di elencare per prime le pagine più rilevanti per la nostra ricerca. La prima pagina proposta, quella alla quale si arriva automaticamente attraverso il pulsante 'Mi sento fortunato', è quella che Google considera più rilevante ai nostri scopi: se siamo effettivamente fortunati, vi troveremo direttamente l'informazione che stiamo cercando. Va detto, comunque, che la tradizionale pagina di risultati è di norma più utile e completa: la maggior parte degli utenti utilizzerà dunque il normale pulsante di ricerca, senza sfidare la fortuna (e l'abilità dei programmatori di Google). Gli utenti più avvertiti, comunqe, preferiranno spesso alla ricerca di base quella svolta per mezzo della pagina di 'Ricerca avanzata': attraverso qualche campo in più e comodi menu a tendina, tale pagina consente un controllo raffinato delle opzioni di ricerca e l'impostazione di ricerche anche assai complesse.
Nell'esempio visualizzato nella figura 69, la nostra ricerca si svolge sulla frase Jane Austen. La ricerca per frase (o, come si dovrebbe dire più propriamente, la ricerca su stringa di caratteri) è ancor più restrittiva (e dunque selettiva) della ricerca in AND: anziché offrirci tutte le pagine in cui compaiono i termini cercati, restituisce tutte le pagine in cui i termini cercati compaiono uno di seguito all'altro, nello specifico ordine indicato. In questo modo, non correremo il rischio di includere fra i nostri risultati pagine che parlino di una Jane diversa da Jane Austen, che magari abita in una località denominata 'Austen'. In generale, come è facile capire, la ricerca per frase è assai comoda quando abbiamo a che fare con nomi e cognomi (attenzione però, soprattutto nel caso dei nomi anglosassoni, alle eventuali iniziali intermedie). La si può svolgere anche attraverso la pagina della ricerca di base, avendo l'accortezza di includere fra apici doppi la stringa di caratteri sulla quale vogliamo condurre la ricerca: nel nostro esempio, nella pagina della ricerca di base dovremmo scrivere "Jane Austen" (doppi apici compresi).
Nel momento in cui scriviamo, una ricerca per termini sulla stringa "Jane Austen" condotta su Google porta a un elenco di circa duecentoventitremila pagine disponibili in rete: fra le altre, pagine dedicate alla scrittrice da università, da appassionati, da librai e case editrici; versioni ipertestuali e testuali di molte fra le sue opere; programmi di corsi universitari dedicati a Jane Austen; bibliografie; articoli accademici che studiano i più disparati aspetti della sua letteratura, e addirittura... barzellette ispirate a Jane Austen, e siti per l'acquisto on-line di vestiti ispirati ai suoi racconti. Per avere un'idea della mole del materiale disponibile, potete dare un'occhiata al curioso sito della 'Republic of Pemberly', alla URL http://www.pemberley.com/. A dimostrazione della continua espansione del Web, basti ricordare che nel settembre 1999 la stessa ricerca (condotta attraverso Altavista, che era all'epoca il motore di ricerca più usato) portava ad un elenco di circa trentasettemila pagine, nel marzo 1998 a un elenco di circa sedicimila pagine, nel 1997 a un elenco di cinquemila pagine, e nel marzo 1996 a un elenco di sole quattromila pagine. Ma vediamo di capire meglio in che forma Google restituisce i propri risultati, e come utilizzarli al meglio. Se non abbiamo modificato il numero dei risultati per pagina nella impostazione della ricerca avanzata, o nella pagina delle preferenze globali (http://www.google.it/preferences/; le preferenze impostate in questa pagina vengono salvate sul nostro computer e richiamate automaticamente alla successiva utilizzazione del servizio), Google restituisce i suoi risultati dieci alla volta. Se disponete di una connessione veloce alla rete, suggeriamo di portare questo valore a trenta: eviterete di cambiare pagina troppo spesso. Il titolo di ognuna delle pagine che soddisfano la nostra ricerca è in blu ed è cliccabile, in modo da poter raggiungere direttamente la pagina desiderata. Sotto di esso compare un breve estratto della pagina (ci aiuta a capire in che contesto sono usati i termini che cerchiamo), e, se la pagina è compresa nell'indice sistematico di Google (che come abbiamo visto è quello di Open Directory), anche la relativa descrizione e categoria. L'integrazione in tal modo realizzata fra motore di ricerca e indice sistematico, che costituisce una novità del 2003, è - va detto - più lineare e di più immediata interpretazione di quella proposta da Yahoo!. Troviamo infine, in verde, l'indirizzo completo della pagina, una stima del suo 'peso' in Kbyte, e il comodissimo link alla 'copia cache' della pagina stessa: nell'indicizzare un sito, infatti, Google conserva sui propri server una copia locale di tutte le pagine trovate. La copia locale può mancare di diverse caratteristiche della pagina originaria (immagini, ecc.), e alcuni link possono non funzionare, ma in molti casi essa consente di arrivare all'informazione che cerchiamo anche quando il sito in questione sia per qualche motivo non raggiungibile, o la pagina sia stata cancellata o modificata.
In alcuni casi può essere utile anche il link 'pagine simili', che sfrutta un algoritmo di 'filtraggio collaborativo' (basato cioè sull'analisi delle abitudini di navigazione degli utenti) elaborato originariamente dalla società Alexa per collegare fra loro siti di argomento analogo. Se siete interessati a reperire siti simili a quello indicato, o a sapere cosa pensano altri navigatori del sito in questione, vi consigliamo tuttavia di svolgere la vostra ricerca direttamente dalla pagina di Alexa (http://www.alexa.com/): i risultati ai quali arriverete sono gli stessi di Google, ma i singoli siti sono accompagnati da una valutazione (non sempre affidabile), da note sul traffico del sito, da brevi recensioni... Alexa è stata acquistata recentemente da Amazon (la maggiore libreria in rete: ne parleremo ampiamente in seguito), che ne ha molto migliorato le caratteristiche e ha in parte limitato la fastidiosa sovrabbondanza di pubblicità che caratterizzava il sito, trasformandolo in uno strumento assai più utile di quanto non fosse fino a qualche mese fa. Ma torniamo a Google. Abbiamo già accennato al meccanismo di 'ranking', ovvero ordinamento per importanza dei risultati. Attraverso di esso, Google - che come abbiamo visto può restituire come risultato di una ricerca anche decine o centinaia di migliaia di pagine - cerca di limitare (per quanto possibile) la fatica di selezionare, all'interno dei risultati, quelli più rilevanti, mostrandoli direttamente per primi. Per determinare l'importanza di una pagina, gli algoritmi di Google utilizzano un insieme piuttosto complesso di fattori: ad esempio, se i termini da noi ricercati sono nel titolo di una pagina, o nelle sue aree attive, o compaiono molto spesso, o se molti degli utenti che hanno svolto la nostra stessa ricerca hanno selezionato quella pagina nell'elenco dei risultati, o se molti altri siti hanno link verso di essa, Google ne fa salire il ranking. La posizione 'elevata' di una pagina all'interno dei risultati di una certa ricerca aumenta ovviamente la visibilità del sito di cui la pagina stessa fa parte, e non c'è da stupirsi del fatto che esistano addirittura dei libri di suggerimenti05 su come 'far salire' la posizione delle pagine del vostro sito all'interno delle liste di risultati di Google. Il progressivo miglioramento nella capacità di Google di ordinare in maniera significativa i risultati delle nostre ricerche ha avuto anche una conseguenza che è bene non sottovalutare: sempre più spesso, infatti, ci si affida a Google - e dunque a un motore di ricerca per termini - anche nel caso di ricerche che in passato si sarebbero svolte in maniera più semplice e produttiva attraverso il ricorso a un indice sistematico. In linea teorica, infatti, un indice sistematico è preferibile rispetto a un motore di ricerca in tutti i casi nei quali la ricerca riguarda argomenti piuttosto generali e ben conosciuti, giacché l'uso di un motore di ricerca fornirebbe in questi casi un numero eccessivo di risultati, che l'utente avrebbe difficoltà a dominare. Ma se questi risultati, pur essendo assai numerosi, sono ordinati in maniera affidabile, l'utente ha (o ha l'impressione di avere) una risposta utile e immediatamente utilizzabile anche ricorrendo a un motore di ricerca. Ed è proprio questo motivo, probabilmente, a spiegare la progressiva ma evidente tendenza degli utenti a preferire l'uso di uno strumento come Google rispetto a quello di uno strumento come Yahoo!. Intendiamoci: non sempre questa preferenza è giustificata: gli utenti alle prime armi spesso non si rendono conto che certe ricerche fornirebbero comunque risultati migliori e più rapidi se condotte attraverso un indice sistematico anziché attraverso un motore di ricerca. Ma non c'è dubbio che i motori di ricerca stiano diventando col tempo strumenti sempre più comodi e potenti. È anche questa evoluzione a spiegare come mai Yahoo!, l'indice sistematico per eccellenza, si stia progressivamente trasformando in uno strumento ibrido al cui interno acquista via via maggiore importanza la ricerca per termini.
Nell'analisi delle funzionalità offerte da Google una menzione particolare merita infine la Google toolbar, plug-in disponibile per Internet Explorer (versione 5 o successiva). Una volta installata (la si scarica dalla pagina http://toolbar.google.com/intl/it/), la toolbar compare come barra aggiuntiva nella porzione superiore della finestra di Explorer. Le funzionalità offerte sono in effetti assai utili: oltre alla disponibilità in ogni momento di una casella per la ricerca su Google (con la possibilità di ricercare non solo pagine Web ma anche immagini, notizie, quotazioni di borsa, la Open Directory, i newsgroup Usenet, e un dizionario inglese), la Google toolbar permette di visualizzare, attraverso una piccola barra verde, il 'Page Rank' - ovvero un indice di attendibilità, talvolta discutibile ma comunque interessante - della pagina sulla quale ci troviamo, di 'votare' il sito (la faccetta sorridente assegna al sito un voto positivo, quella corrucciata un voto negativo), di tradurlo (come ogni traduzione automatica, anche quella di Google è tutt'altro che perfetta; le funzionalità di traduzione automatica - di una pagina Web o di un brano di testo - sono disponibili anche alla pagina http://www.google.com/language_tools/; al momento in cui scriviamo le lingue 'conosciute' da Google sono italiano, inglese, tedesco, francese e portoghese), di svolgere ricerche all'interno della pagina o del sito sul quale ci troviamo, di ricercare automaticamente pagine simili, e infine (assai utile nel caso di pagine un po' lunghe e complesse) di evidenziare automaticamente all'interno della pagina le parole cercate. L'attivazione di alcune funzionalità della barra - ad esempio la possibilità di votare i siti - presuppone ovviamente che i relativi dati vengano comunicati a Google. La comunicazione avviene in forma anonima e le garanzie offerte sulla privacy dei dati sono ben illustrate sul sito; in ogni caso, le funzionalità che richiedono questo tipo di comunicazione possono essere facilmente disattivate dal menu 'Opzioni' della toolbar. ...e ancora GoogleAbbiamo già notato come negli ultimi anni Google si sia trasformato nel più importante strumento di ricerca su Web, tanto da acquistare un ruolo in qualche misura anche 'politico'. I suoi meccanismi di ordinamento dei risultati influenzano infatti in maniera sempre più evidente le abitudini di navigazione di moltissimi utenti: un sito 'poco visibile' su Google avrà molti meno visitatori di quelli che magari meriterebbe, e un sito molto visibile potrebbe averne molti di più di quanti non sarebbe auspicabile. Google, insomma, svolge anche - e quasi inevitabilmente - una funzione di selezione e di filtro. Davanti alla sterminata quantità di informazioni disponibile in rete, l'uso di strumenti di selezione è certo necessario, e nel complesso Google svolge assai bene il suo lavoro: le divinità del Web ci hanno finora protetto dal rischio che queste funzioni fossero svolte da società (non facciamo nomi, ma non sarebbe difficile farli...) che potrebbero essere guidate da motivazioni assai più decisamente commerciali. Ma il ruolo-chiave di Google non deve essere sottovalutato: anche un motore di ricerca non è mai uno strumento totalmente neutrale. Per comprendere la centralità che Google va assumendo nello sviluppo dei servizi di rete va ricordato anche il ruolo delle 'Google API': si tratta di librerie di funzioni che interessano in primo luogo i programmatori, e che consentono di inserire la capacità di svolgere ricerche attraverso Google all'interno di programmi e servizi Web. Dal punto di vista dell'utente, la diffusione delle Google API - la cui registrazione è gratuita se vengono utilizzate per un massimo di mille ricerche al giorno - significa che sempre più spesso funzionalità di ricerca di ogni genere passeranno attraverso Google. Anche in questo caso, alcuni commentatori hanno sottolineato il ruolo di possibile 'grande fratello' che viene a delinearsi per il motore di ricerca. La gestione di Google per ora non sembra giustificare queste preoccupazioni, ma è bene comunque tenerle presenti. Passando a temi più leggeri, la disponibilità delle Google API e l'enorme successo di Google hanno favorito lo sviluppo di un gran numero di siti che ne sfruttano le caratteristiche e le potenzialità in modo curioso o peculiare; può essere divertente (e in qualche caso anche utile) ricordarne qualcuno. Una raccolta ancor più ampia di segnalazioni di questo genere è sul sito Elgoog (http://www.elgoog.nl/), ormai un vero e proprio punto di riferimento per gli appassionati. La Google dance è quella che fanno i tre server principali di Google quando non sono perfettamente allineati, e forniscono dunque per una data ricerca un numero di risultati discordante. Avviene circa ogni 28 giorni, assicurano gli esperti, e se siete fortunati potrete osservarla attraverso la pagina http://www.google-dance-tool.1hut.com/. Il GoogleWhacking (http://www.googlewhack.com/) è la ricerca di termini o espressioni per i quali Google fornisce una sola, singola occorrenza. Una volta segnalato, il termine viene spesso 'bruciato', dato che molti siti di GoogleWhacking sono anch'essi indicizzati da Google. La lista principale, il Whack Stack (http://www.googlewhack.com/tally.pl), non è comunque indicizzata e conta oltre 110.000 termini, alcuni dei quali vere e proprie perle (cosa ne dite di 'rancorous venusians'?). Google Fight (http://www.googlefight.com/) è il confronto del numero di occorrenze di due termini all'interno degli indici di Google. In genere, si tratta di nomi di persone (ricordate gli apici doppi!). Un tipo particolare di Google Fight è quello in cui si cerca di trovare due nomi con lo stesso numero di occorrenze. I molti Google-dipendenti troveranno poi utile il sorprendente GoogleBrowser tridimensionale (http://www.touchgraph.com/TGGoogleBrowser.html), cucineranno basandosi sui risultati delle ricerche svolte all'indirizzo http://theory.stanford.edu/~amitp/recipe.html, non avranno difficoltà a utilizzare la versione 'speculare' di Google all'indirizzo http://elgoog.rb-hosting.de/, e leggeranno i racconti di H.P. Lovecraft con l'aiuto della pagina http://www.cthuugle.com/. Funzionalità curiose si trovano anche all'interno del sito stesso di Google, e in particolare nella sezione dei Google labs (http://labs.google.com/). Ad esempio la pagina che propone uno slide show dei risultati trovati (http://labs.google.com/gviewer.html; serve una connessione veloce...), o quella che vi aggiunge una raccolta di riferimenti e citazioni da altri siti (http://labs.google.com/cgi-bin/webquotes/). O ancora il Google Glossary (http://labs.google.com/glossary/), ottimo per la ricerca di definizioni. Merita un'occhiata anche la sezione dedicata alle Special Searches (http://www.google.com/options/specialsearches.html). Puro shopping, invece, in un altro servizio beta non a caso lanciato in stagione natalizia: Froogle (http://froogle.google.com/froogle/), strumento per la ricerca di tutto quel che si vende in rete.
Alltheweb e ScirusAlltheweb (http://www.alltheweb.com/), pur se sicuramente meno noto, rappresenta nel momento in cui scriviamo l'alternativa probabilmente migliore alle fenomenali capacità di Google. Realizzato da una società nata in Europa, la norvegese Fast (http://www.fast.no), Alltheweb è stato acquistato nel 2003 dalla statunitense Ouverture (http://www.overture.com/), una delle società leader del settore, a sua volta acquistata da Yahoo! nel luglio 2003. Dichiara di indicizzare a fine agosto 2003 oltre 3 miliardi di pagine. La ricerca semplice avviene attraverso una pagina assai simile a quella di Google: le linguette permettono di scegliere la base di ricerca (ovviamente la più usata è la ricerca su Web), i termini da cercare vanno indicati nel campo centrale, e il pulsante 'Search' avvia la ricerca. Come avviene su Google, nel caso siano indicati più termini la ricerca avviene in AND (sono dunque restituite solo le pagine in cui compaiono entrambi i termini ricercati), mentre gli apici doppi possono essere usati per la ricerca su una stringa di caratteri. Se la pagina trovata dispone di un riassunto del contenuto (chi realizza pagine web può sempre prevederne uno, utilizzando il metadato 'description'), Alltheweb lo visualizza assieme a un estratto della porzione della pagina in cui compaiono i termini cercati. Ma il vero punto di forza di Alltheweb è rappresentato dal modulo di ricerca avanzata: ricchissimo di opzioni, tanto da risultare più completo di quello di Google, esso permette di impostare ricerche estremamente sofisticate. Chi ha familiarità con l'uso delle espressioni booleane può utilizzarle direttamente, ed è possibile creare filtri di ogni tipo: per data, per tipologia delle pagine, per domini di provenienza, e così via. Fra gli operatori utilizzabili è presente anche 'rank', che permette di influenzare l'ordine di presentazione dei risultati dando la precedenza a quelli nei quali compaiono uno o più termini aggiuntivi. Altra caratteristica nella quale Alltheweb eccelle è la personalizzazione dell'interfaccia: l'utente con un po' di pratica in HTML può addirittura crearsi la propria, mentre gli utenti meno esperti possono comunque scegliere la preferita fra le varie 'pelli' che Alltheweb mette a disposizione. Il modulo che gestisce questi 'cambiamenti di pelle' (tutti basati sull'uso di fogli stile CSS: ne parleremo nel seguito del manuale) si chiama Alchemist, e alla pagina http://www.alltheweb.com/help/alchemist/gallery.html è disponibile una raccolta piuttosto ampia di modelli diversi. Quanto alle lingue, Alltheweb è disponibile con interfaccia in 49 lingue diverse. Anche Alltheweb può essere integrato direttamente nel browser, anche se le funzionalità aggiunte sono meno numerose di quelle offerte dalla Google toolbar. In compenso, l'integrazione è possibile non solo con Explorer ma anche con Netscape, Mozilla e Opera. Informazioni su queste funzionalità sono alla pagina http://www.alltheweb.com/help/tools/. Due caratteristiche recentemente introdotte in Alltheweb meritano di essere ricordate. La prima si chiama 'URL Investigator': se nel campo di ricerca viene inserito l'indirizzo di una pagina web, la ricerca restituisce una serie di utili informazioni sul sito: chi lo ha registrato, quanti sono i link che lo raggiungono dall'esterno, e addirittura (attraverso il link a un servizio sul quale avremo occasione di tornare: Archive.org) quale era l'apparenza della pagina in passato. La seconda si chiama 'Look it up': attraverso il già citato servizio Dictionary.com è possibile controllare il significato di qualsiasi termine (inglese) compaia fra le chiavi di ricerca. Infine, vorremmo segnalare uno strumento davvero prezioso che ha un collegamento 'storico' con Alltheweb, dato che è stato anch'esso sviluppato dalla già ricordata società norvegese Fast. Si tratta di un motore di ricerca denominato Scirus, specializzato nell'informazione scientifica di qualità. La base di dati indicizzata da Scirus è costituita da un sottoinsieme selezionato di pagine Web (composto prevalentemente da siti accademici e di ricerca) e dai record di una raccolta piuttosto ampia di risorse specialistiche. Eccone l'elenco, tratto dalla presentazione del motore di ricerca (i dati sono quelli del febbraio 2003):
Come si vede, Scirus ha una interessante caratteristica, già sperimentata da uno strumento di ricerca fra i più gloriosi, che ha purtroppo rinunciato negli ultimi anni a molte fra le sue funzionalità più interessanti: Northern Light (http://www.northernight.com/): l'integrazione fra ricerca sul web e ricerca su basi di dati specializzate accessibili via web. Il problema dell'integrazione fra questi due tipi di ricerca è una delle grandi questioni aperte nel campo dell'uso di Internet come risorsa per il reperimento di informazioni qualificate, e probabilmente uno dei settori sui quali si lavorerà di più nei prossimi anni. Altri motori di ricercaYahoo! (http://www.yahoo.com/). Abbiamo già parlato abbondantemente di Yahoo! a proposito di indici sistematici, e abbiamo osservato come esso permetta di svolgere anche ricerche su pagine Web, offrendo dunque, accanto all'originaria caratteristica di Web directory, anche quella di vero e proprio motore di ricerca. Quando è utilizzato come motore di ricerca, Yahoo! fa ricorso - nel momento in cui scriviamo - alla base dati di Google, società con la quale (nonostante l'evidente concorrenza fra i due servizi, ciascuno dei quali vorrebbe offrire sia un indice sistematico sia la possibilità di svolgere ricerca per termini) Yahoo! ha stabilito un accordo commerciale valido per tutto il 2003. Nel contempo, tuttavia, Yahoo! ha fatto due mosse a sorpresa: innanzitutto, ha acquistato la Inktomi. Nata nel 1996 da un gruppo di ricerca dell'Università di Berkeley, la Inktomi, pur non gestendo direttamente un portale di ricerca, ha realizzato (e venduto a terzi, Microsoft compresa) un servizio di ricerca su Web di tutto rispetto. Nella primavera 2003, la versione denominata Web Search 9 dei servizi Inktomi dichiara di essere «progettata per scoprire ed analizzare» oltre tre miliardi di pagine Web. Una formulazione piuttosto ambigua, che intende evidentemente porre i servizi Inktomi sullo stesso livello di quelli di Google: basta fare qualche ricerca, tuttavia, per rendersi conto che la base dati effettiva della Inktomi - pur essendo indubbiamente assai ampia - resta per ora più ristretta di quella di Google. Tra i servizi che utilizzano il motore Inktomi, oltre a Microsoft, è ad esempio la ricerca su Web di Looksmart. Nel luglio 2003 è poi arrivato il secondo colpo di scena: Yahoo! ha acquistato anche Ouverture, a sua volta proprietaria di Alltheweb e di Altavista. Con queste acquisizioni, Yahoo! sembra muoversi decisamente verso una concorrenza a Google anche nel campo della ricerca per termini: è probabile dunque che in futuro le funzionalità di ricerca su Web di Yahoo! siano destinate a cambiare. MSN Search (http://search.msn.com/). Anche di MSN Search abbiamo parlato a proposito di indici sistematici. Se usato nella sua modalità avanzata (attraverso la pagina http://search.msn.com/advanced.aspx), tuttavia, il sito di MSN Search permette anche una ricerca su Web discretamente flessibile, basata sulla base dati di Inktomi integrata da alcuni strumenti di gestione e ordinamento proprietari. In particolare, è possibile utilizzare operatori booleani e anche il cosiddetto 'stemming' o troncatura dei termini, che permette di cercare contemporaneamente tutti i termini che hanno in comune una stessa radice (ad esempio, una ricerca con chiave 'impost' e stemming abilitato troverà sia le pagine in cui compare il termine 'imposta', al singolare, sia quelle in cui compare il termine 'imposte', al plurale. Attenzione, però: troverà anche le pagine in cui compare il verbo 'impostare' o i termini 'impostura', 'impostore', 'impostazioni', ecc.: la troncatura è dunque una funzionalità che va usata con una certa attenzione, se non vogliamo vedere esplodere il numero dei risultati ottenuti!). Altavista (http://www.altavista.com/) è il risultato di un progetto di ricerca iniziato nell'estate del 1995 nei laboratori di Palo Alto della Digital, una delle aziende 'storiche' nel mondo dell'informatica, ed è stato fra il 1997 e il 1999 - prima dell'avvento di Google - il servizio leader nel campo dei motori di ricerca su Web. La crisi della new economy e la concorrenza di Google lo hanno tuttavia colpito duramente, e il sito ha perso senz'altro diverse posizioni nella ideale (e comunque in parte soggettiva) 'classifica' dei migliori motori di ricerca. Nell'aprile 2003 il motore di ricerca è stato acquistato dalla società Ouverture, la stessa che ha acquistato Alltheweb, e che come abbiamo visto è stata acquistata a sua volta da Yahoo! nel luglio 2003. Altavista è stato fra i primi siti a offrire un interessante servizio gratuito di traduzione automatica, denominato Babelfish e basato sul programma Systran: assieme al titolo e all'abstract delle pagine trovate, nell'elenco dei risultati di una ricerca fornito da Altavista abbiamo così a disposizione un link 'Translate' che ci permetterà di impostare la lingua nella quale vogliamo visualizzare la pagina reperita. Il servizio di traduzione può anche essere usato autonomamente, dalla pagina http://babelfish.altavista.com/. Non aspettatevi comunque miracoli: le traduzioni automatiche lasciano ancora molto a desiderare. Ask Jeeves (http://www.ask.com/) è divenuto famoso per la sua capacità di rispondere a ricerche in linguaggio naturale (ovviamente in inglese), del tipo "What is gravitation theory?", offrendo una selezione non troppo ampia ma altamente rilevante di pagine. La base dati su cui si basa è quella del motore di ricerca Teoma (http://www.teoma.com/), che ha come obiettivo non tanto la completezza quanto la rilevanza dei risultati: non si tratta della scelta migliore nel caso di ricerche su termini molto esoterici, ma se la nostra è una ricerca 'comune', relativa a temi largamente presenti in rete, Ask Jeeves può effettivamente offrire una valida alternativa a motori di ricerca più noti. Comoda anche la capacità di fornire suggerimenti su possibili 'ricerche correlate', che potrebbero permetterci di restringere o meglio specificare le chiavi di ricerca utilizzate. Poco rilevante dal punto di vista teorico ma assai piacevole da quello estetico è infine la bellissima grafica anni '50 del sito, che fa della home page di Ask Jeeves una delle più eleganti disponibili su Web. HotBot (http://www.hotbot.com/) è nato nel 1996 per iniziativa di HotWired (http://www.hotwired.com/), controparte in rete della rivista Wired e, come la sorella su carta, sito 'di culto' per molti fra i nuovi profeti del digitale. Caratterizzato da una interfaccia coloratissima e divertente, HotBot è stato fra i primi motori di ricerca a mettere a disposizione dell'utente possibilità di ricerca veramente avanzate, e ha goduto di una notevole popolarità fra gli utenti più avanzati della rete fino all'avvento di Google; anche in questo caso, la concorrenza di Google e la crisi della net economy, aggiunte ad alcune scelte discutibili della Terra Lycos, la società nata dall'acquisto di Lycos da parte di Terra Network a fine 1998, hanno portato a una rapida perdita di competitività da parte del sito. Oggi HotBot permette di svolgere ricerche attraverso le basi dati di Google, Alltheweb, Inktomi e Teoma, ed è dunque, più che un motore di ricerca autonomo, uno strumento abbastanza comodo per comparare i risultati forniti da motori di ricerca diversi a una stessa ricerca. Lycos (http://www.lycos.com/) è fra i motori di ricerca più 'anziani'. Nato come progetto sperimentale presso la Carnegie Mellon University sotto la direzione di Michael Mauldin, si è trasformato nel giugno 1995 in una vera e propria impresa, la Lycos Inc., diventata Terra Lycos a seguito della fusione con Terra Networks nel 2000. La concorrenza prima di Altavista e poi di Google ha fortemente penalizzato Lycos, che si è rivelato incapace di trarre vantaggio dall'acquisto di HotBot avvenuto a fine 1998. Oggi Lycos svolge le proprie ricerche attraverso la base dati di Alltheweb e costituisce dunque - se utilizzato come motore di ricerca - poco più che un'interfaccia alternativa per l'accesso a tale risorsa. Per finire, due parole sui motori di ricerca italiani: a differenza di quanto avviene per alcuni aspetti degli indici sistematici, un motore di ricerca - limitandosi a verificare meccanicamente in quali pagine Web compaia il termine ricercato - non è di per sé una risorsa legata a un particolare linguaggio. Per questo motivo, andando a spulciare fra i siti italiani che offrono la possibilità di svolgere ricerche per termini (e sono parecchi!) troveremo quasi sempre, più o meno nascosta, la presenza di uno dei motori di ricerca sopra ricordati. Così, ad esempio, Arianna (http://arianna.libero.it/), Excite.it (http://www.excite.it/), Tiscali (http://www.tiscali.it/) si affidano ad Alltheweb; Kataweb (http://www.kataweb.it/), Supereva (http://www.supereva.it/), Virgilio (http://www.virgilio.it/), Yahoo!.it (http://www.yahoo.it/) fanno ricorso a Google, e MSN.it (http://www.msn.it/) utilizza la base dati della Inktomi. Naturalmente, ciò non vuol dire che questi siti non offrano altri contenuti e servizi pensati per l'utente italiano: quasi tutti lo fanno, e proprio questi servizi aggiuntivi (ad esempio le notizie di agenzia, o la presenza di strumenti di comunità come chat e gruppi di discussione, o ancora la disponibilità di un buon servizio di Web mail) possono determinare la preferenza dell'utente per l'uno o per l'altro sito. Ma su questi temi torneremo in seguito, quando parleremo di portali. Alcune metarisorseNonostante il ruolo preponderante di Google come strumento per la ricerca su Web, ha conservato il suo rilievo anche un altro tipo di risorsa che può essere utile ricordare in conclusione: quella rappresentata dai cosiddetti strumenti di 'metaricerca'. Prima di parlarne, però, vorremmo segnalare tre siti che il 'ricercatore di rete' dovrebbe tenere d'occhio. Il primo è il Search Engine Watch, all'indirizzo http://www.searchenginewatch.com/; come indica il nome, questo sito si propone di monitorare in maniera sistematica caratteristiche e prestazioni dei diversi motori di ricerca. Si tratta di una risorsa ricca di notizie e suggerimenti, che raccoglie in un'unica sede i link a tutte le recensioni di motori di ricerca da parte delle principali riviste e dei principali siti 'tecnici' esistenti in rete. Incredibile ma vero, qualcosa di simile esiste anche nel nostro paese (e si tratta del secondo sito di interesse generale che vogliamo segnalarvi): all'indirizzo http://www.motoridiricerca.it/ trovate una rassegna completa dei principali motori di ricerca, corredata da indicazioni sulle rispettive sintassi, da suggerimenti per il loro uso, e da dati di raffronto. Alcune pagine del sito sono aggiornate, altre lo sono meno, ma nel complesso si tratta di una risorsa preziosa per l'internauta nostrano. Infine, un'altra pagina utile per un orientamento generale sulla ricerca in rete è offerta da Refdesk.com all'indirizzo http://www.refdesk.com/newsearch.html. Vi si troveranno link a una serie di tutorial - selezionati con buona competenza - e l'elenco di un notevole numero di strumenti di ricerca, organizzati per categorie. Veniamo ora ai veri e propri strumenti di metaricerca. Le 'metaricerche' consistono, in sostanza, nell'inviare in maniera sequenziale o contemporaneamente a più motori di ricerca il termine o i termini che ci interessano. L'invio sequenziale è analogo alla consultazione successiva di più motori di ricerca: è comodo poterlo fare da un'unica pagina, anche per confrontare i risultati ottenuti attraverso strumenti diversi, ma il valore aggiunto fornito da una risorsa di questo tipo è comunque minimo. Potete dare un'occhiata, fra i servizi che rientrano in questa categoria, al già citato (e già glorioso) HotBot (http://www.hotbot.com/), a EZ-Find (http://www.theriver.com/TheRiver/Explore/ezfind.html), alla funzione 'Search' del comodissimo 'aggregatore di servizi' I-tools (http://www.itools.com/, la pagina di metaricerca sequenziale è all'indirizzo http://www.itools.com/search/), e a Starting Point (http://www.stpt.com/pwrsrch.asp). Un discorso a parte merita il ricchissimo Fagan Finder (http://www.faganfinder.com/). Considerarlo uno strumento di ricerca sequenziale è riduttivo: si tratta piuttosto di un indice ragionato - e assai ben costruito - che comprende un'ampia selezione di strumenti di ricerca, di metaricerca e di reference, con la possibilità di selezionare e compiere le ricerche direttamente dall'interno delle sue pagine. Se dovessimo indicare un singolo punto di partenza ai patiti della ricerca in rete, Fagan Finder - che offre anche un eccellente 'metatraduttore automatico' - sarebbe probabilmente uno dei primi siti da considerare: dategli assolutamente un'occhiata. La metaricerca vera e propria, come è facile capire, consiste comunque nella possibilità di consultare contemporaneamente diversi motori di ricerca, in modo da raccoglierne i risultati in un'unica lista di risposte; soluzione utile soprattutto se i risultati ottenuti vengono integrati in maniera intelligente. I servizi di questo tipo sono numerosissimi e di diversa natura, tanto che ci sembra senz'altro preferibile segnalare innanzitutto la pagina di Searchenginewatch che ne recensisce i migliori (http://www.searchenginewatch.com/links/article.php/2156241) e quella di Yahoo! che ne raggruppa oltre cento: http://dir.yahoo.com/ Computers_and_Internet/ Internet/ World_Wide_Web/ Searching_the_Web/ Search_Engines_and_Directories/ All_in_One_Search_Pages/. Prima di esaminarne alcuni, un'osservazione generale: il limite principale dei metamotori è che nella maggior parte dei casi, per operare l'aggregazione dei risultati in tempi ragionevoli, la ricerca viene limitata solo ai primi fra i risultati restituiti dai servizi di ricerca primaria. Ciò significa che in genere la ricerca conduce a un numero di risultati che non è, come ci si potrebbe aspettare, la somma 'intelligente' di quelli ottenuti attraverso tutti i motori di ricerca utilizzati, ma piuttosto un loro sottoinsieme limitato (pur se altamente significativo). Fra i metamotori più efficaci ricordiamo Ithaki (http://www.ithaki.net/), disponibile in diverse lingue (Italiano compreso), con la possibilità di effettuare metaricerche limitate a una specifica area geografica (ad esempio a risorse che riguardano l'Italia), di raggiungere una versione Wap per telefonini cellulari (utile soprattutto per la ricerca 'mobile' di notizie; l'indirizzo da digitare nel cellulare è http://ithaki.net/wap/) e con la possibilità di impostare diversi tipi di metaricerca; Vivisimo (http://vivisimo.com/), ottimo nell'organizzare in categorie i risultati ottenuti; ProFusion (http://www.profusion.com/), nato da un progetto dell'Università del Kansas e ora di proprietà della società Intelliseek, che nella schermata di ricerca avanzata permette di impostare in maniera assai completa il tipo di metaricerca e le sue fonti. Meritano una menzione anche Fazzle (http://www.searchonline.info/), Ixquick (http://ixquick.com/), Search.com (http://www.search.com/), Meta Crawler (http://www.metacrawler.com/), Infonetware (http://www.infonet-ware.com/, anch'esso con la capacità di organizzare in categorie tematiche i risultati ottenuti). Per la colorata interfaccia grafica e la rappresentazione bidimensionale dello spazio informativo costituito dai risultati ottenuti si segnala anche Kartoo, all'indirizzo http://www.kartoo.com/. Va detto infine che per effettuare metaricerche non è necessario collegarsi a un particolare sito in rete: è anche possibile ricorrere a uno dei molti programmini 'agenti', in grado di interrogare automaticamente i motori di ricerca per i quali li abbiamo configurati, e di fornirci, integrati, i relativi risultati. Ne parleremo fra breve, occupandoci del futuro della ricerca in rete. Naturalmente tutti questi tipi di metaricerche, presentando in genere all'utente una interfaccia unica, possono impedire di utilizzare fino in fondo i linguaggi propri dei diversi motori di ricerca; e si tratta di un limite spesso notevole. L'integrazione fra motori di ricerca diversi è comunque senza dubbio una delle strade da esplorare per cercare di organizzare l'informazione disponibile su Web, ed è probabile che in futuro gli strumenti di metaricerca acquisteranno una rilevanza e una flessibilità maggiori di quelle attuali. Gli strumenti di ricerca offerti dal browserSia Netscape sia Explorer incorporano alcuni strumenti di ricerca potenzialmente interessanti, anche se nessuno di essi risulta, a conti fatti, davvero preferibile rispetto all'uso 'tradizionale' di un buon motore di ricerca. È infatti presente in entrambi un pulsante 'Cerca', o 'Search', che può sembrare a prima vista attraente: non sarà una buona strada per evitare di perdersi fra motori di ricerca e indici sistematici di risorse, e per effettuare efficaci ricerche guidate? La risposta è (parzialmente) positiva solo a condizione di 'personalizzare' la funzionalità di questi bottoni, cosa fortunatamente possibile. In caso contrario, Explorer e Netscape imposteranno per noi il motore di ricerca: la ricerca di Explorer verrà condotta (come potevamo aspettarci) attraverso MSNSearch, quella di Netscape attraverso la pagina di ricerca di Netscape stesso, impostata su Lycos. Insomma: la scelta dei motori di ricerca offerti sembra rispondere più alle strategie commerciali e alle alleanze rispettive di Microsoft e Netscape che all'esigenza di dare all'utente uno strumento davvero completo. Viene poi nascosta la sintassi di ricerca propria di ogni singolo strumento, col prevedibile risultato di 'indebolire' le funzionalità a nostra disposizione. Il nostro suggerimento, dunque, è innanzitutto quello di far ricorso a questi strumenti solo dopo aver acquisito una buona familiarità con i principali motori di ricerca e indici sistematici in rete. E in secondo luogo di personalizzare le funzionalità di ricerca del browser. Diversi motori di ricerca offrono procedure automatiche in grado di compiere queste operazioni, integrando nei due browser più diffusi le proprie specifiche funzionalità. Se avete uno strumento di ricerca preferito, consultate dunque le relative pagine di help: molto probabilmente troverete indicazioni al riguardo. Ci sentiamo comunque di prevedere che la scelta della maggior parte dei lettori si indirizzerà verso Google o Alltheweb. Nel caso di Google, la già ricordata Google toolbar offre funzionalità assai maggiori di quelle di un semplice pulsante di ricerca, ma è anche possibile la personalizzazione del solo pulsante: troverete le istruzioni per farlo - sia per Explorer sia per Netscape - alla pagina http://www.google.it/options/defaults.html, sezione 'Make Google your default search engine'. Nel caso di Alltheweb, la pagina da utilizzare è invece la già citata http://www.alltheweb.com/help/tools/. Chi volesse ulteriormente 'potenziare' le capacità di ricerca disponibili direttamente dall'interno del proprio browser, può infine consultare la lista di strumenti e programmi aggiuntivi disponibile nella sezione 'Browser - Searchboots' di TuCows. Segnaliamo in particolare il programmino gratuito GGSearch, che offre in un'unica e compatta interfaccia una scelta assai ampia delle funzionalità di ricerca di Google, comprese quelle più avanzate. L'indirizzo dal quale scaricarlo è http://www.frysianfools.com/ggsearch/. Ma con programmi di questo genere ci avviciniamo ormai al campo, affascinante, degli agenti di ricerca: un settore che merita senz'altro una trattazione separata. Prima, però, vorremmo soffermarci su due tipi particolari di ricerca, sui quali è bene fornire alcune informazioni specifiche: la ricerca di immagini e la ricerca di notizie. La ricerca di immaginiCome sappiamo, l'informazione disponibile su Internet non è soltanto testuale: i contenuti multimediali ne costituiscono una componente essenziale. Della ricerca di file sonori e musicali abbiamo già parlato, ricordando anche la particolare funzione che hanno al riguardo i programmi peer-to-peer. Cosa possiamo dire per quanto riguarda le immagini?
Ebbene: la maggior parte dei principali motori di ricerca - a cominciare da Google - ha la capacità di svolgere ricerche specifiche sulle immagini. Di norma, per accedere a questa funzionalità bisogna selezionare una linguetta denominata 'Images' o 'Immagini', presente nella pagina principale del motore di ricerca. Una volta compiuta tale operazione, i termini di ricerca inseriti verranno utilizzati per ricercare i nomi, le descrizioni e il testo di contorno delle immagini inserite su Web. Occorre tener ben presente, a questo riguardo, la distinzione fra informazione e metainformazione della quale abbiamo già parlato: le immagini, infatti, sono qualcosa di ben diverso dal testo, ma la loro ricerca non può prescindere da una descrizione testuale. Ciò significa che la ricerca non viene effettuata direttamente sull'informazione primaria che desideriamo reperire (le immagini, appunto) ma su metainformazione testuale che viene associata - di norma in maniera assai disomogenea e occasionale - alle immagini stesse dagli autori del sito. Per questo motivo, gli strumenti per la ricerca di immagini (come del resto quella di file sonori o contenuti video) possono offrire una completezza ancor minore di quella garantita dai tradizionali motori di ricerca. Naturalmente, anche la modalità di presentazione dei risultati di una ricerca su immagini sarà diversa da quella propria della ricerca su pagine Web. Le immagini che soddisfano i nostri criteri di ricerca ci vengono così di norma proposte sotto forma di 'thumbnails', e cioè attraverso una anteprima di dimensioni ridotte. Ricordiamo che le immagini inserite su Web non sono necessariamente - anzi, non sono quasi mai - libere da diritti: se le usiamo per scopi personali o per una ricerca scolastica, probabilmente nessuno verrà a casa ad arrestarci (anche se l'evoluzione sempre più restrittiva delle norme relative alla protezione dei diritti d'autore - ma forse sarebbe più corretto chiamarli 'diritti di editore' - non lascia davvero ben sperare). Ma se vogliamo inserirle in un prodotto informativo a pagamento, o anche solo in un sito a larga visibilità, sarà bene assicurarci di poterlo fare. Va detto, a questo proposito, che su Web esistono anche diversi servizi di vendita 'professionale' di immagini, attraverso basi di dati iconografiche proprietarie che permettono la ricerca delle immagini, la loro visualizzazione e l'acquisto - in genere a prezzi non proibitivi - dei relativi diritti d'uso. Una delle maggiori è Corbis, all'indirizzo http://www.corbis.com/. La ricerca di notizieInternet è ormai, come si è già accennato fin dall'introduzione, anche un potentissimo strumento di informazione sull'attualità del momento. Con il vantaggio di integrare l'aggiornamento continuo, in alcuni casi davvero minuto per minuto, tradizionalmente proprio dei media di flusso come radio e televisione, con la libertà di scegliere non solo la fonte informativa preferita ma anche i singoli temi e i singoli contenuti che di volta in volta interessano, tradizionalmente propria dei media a stampa come giornali e riviste. Su questi aspetti di Internet avremo occasione di tornare in diverse occasioni nella sezione del libro dedicata ai temi e percorsi di navigazione. Ma in questa sede, parlando di ricerca in rete, può essere opportuno dire qualcosa sugli strumenti disponibili per selezionare e ricercare contenuti all'interno del flusso continuo di notizie pubblicate nelle migliaia di siti Web dedicati all'attualità giornalistica. Strumenti che si sono moltiplicati fra il 2002 e il 2003, e costituiscono probabilmente una delle novità più interessanti del Web. Il posto d'onore spetta probabilmente anche in questo caso a Google, che - nella sua versione inglese - ha inaugurato nel 2002 una nuova sezione dedicata proprio alle News. Vi si accede attraverso l'apposita linguetta 'News' disponibile sulla pagina principale del sito (se partite dalla versione italiana di Google, dovete prima cliccare sul link 'Google in English' disponibile in fondo alla home page). Se il servizio avrà successo (come sembra probabile), possiamo aspettarci di vederlo comparire nel prossimo futuro anche in versioni 'nazionali'06. Google News offre due funzionalità che è bene concettualmente tenere distinte (anche se sono di fatto integrate all'interno del sito): quella di aggregatore di notizie, e quella di motore di ricerca su notizie. Consideriamole separatamente. Nella sua funzione di aggregatore, Google News offre una pagina che potrebbe assomigliare a quella di tanti altri siti giornalistici: le notizie più importanti in evidenza, sezioni tematiche, alcune foto. La particolarità è che i contenuti non sono prodotti da una redazione interna, ma sono tutti raccolti da altri siti e servizi giornalistici presenti in rete. La pagina è generata in maniera totalmente automatica: al posto dei redattori umani c'è un programma assai sofisticato che analizza a ciclo continuo oltre 4.500 fra i principali e più aggiornati siti giornalistici di tutto il mondo (purché in lingua inglese), seleziona le notizie più recenti e quelle in maggiore evidenza, confronta attraverso algoritmi di analisi testuale gli articoli tratti dalle diverse fonti per raggrupparli in aggregazioni tematiche, sceglie uno di tali articoli come testo di riferimento dal quale estrarre il titolo della notizia, e provvede all'impaginazione, dando maggiore risalto alle tematiche in evidenza nel maggior numero delle fonti analizzate. Il risultato è uno specchio piuttosto fedele dell'attualità del momento, aggiornato circa ogni dieci minuti, che offre al lettore la possibilità di approfondire gli argomenti desiderati attraverso il ricorso a un ventaglio davvero larghissimo di fonti.
Naturalmente, per poter svolgere il proprio lavoro, un servizio come quello di Google News ha bisogno dell'autorizzazione all'uso di contenuti prodotti da altri. Ma la stragrande maggioranza dei siti giornalistici in rete fornisce ben volentieri tale autorizzazione, ovviamente limitata ai contenuti gratuiti del sito. Una volta inserita informazione ad accesso libero in rete, infatti, è interesse dello stesso sito che l'ha prodotta che essa abbia il massimo di visibilità. La condizione, ovviamente, è che la fonte sia indicata in maniera esplicita, di norma anche attraverso un link all'articolo originale. Per incoraggiare tale pratica, un numero sempre maggiore di siti giornalistici (e non solo) offre dei 'canali' informativi che consentono il prelievo automatico dei propri contenuti, e il loro inserimento automatico nelle pagine di altri siti. Tale pratica viene indicata con il nome inglese di 'syndication', e conosce in questi mesi una vera e propria esplosione. Ma del moltiplicarsi di queste 'agenzie di stampa' su Web preferiamo occuparci nella sezione sui weblog, giacché essa riguarda non solo i siti giornalistici 'affermati' ma anche una pluralità di altre fonti: rimandiamo dunque il lettore a tale sezione per un ulteriore approfondimento di queste tematiche. La funzione di ricerca di Google News avviene sulla base di dati costituita da tutte le notizie raccolte dall'aggregatore nel corso degli ultimi trenta giorni. Si tratta dunque dello strumento ideale da utilizzare se vogliamo recuperare nomi, informazioni, commenti su fatti di attualità. La funzione di ricerca su notizie di attualità è offerta anche da diversi altri strumenti, che spesso allargano il ventaglio delle fonti considerate includendovi - accanto ai servizi giornalistici professionali - siti amatoriali di informazione e di commento. Anche su questi strumenti torneremo dunque nel capitolo sui Weblog; in questa sede ci limitiamo a segnalarne uno, Daypop (http://www.daypop.com/). Per chiudere, può essere utile segnalare qualche sito che fornisce indici sistematici di risorse legate all'attualità giornalistica: la World News Guide offerta dal sito Web del giornale inglese Guardian è uno degli strumenti migliori in questo campo, ed è consultabile all'indirizzo http://www.guardian.co.uk/ worldnewsguide/; utili sono anche i siti Mediachannel (http://www.mediachannel.org/ links/ links-frameset.html) e HeadlineSpot (http://www.headlinespot.com/). Il futuro della ricerca: gli agentiLa maggior parte degli strumenti di ricerca in rete fin qui considerati presuppone un utente estremamente 'impegnato' nel processo di individuazione dell'informazione che lo interessa, e presuppone una ricerca per così dire 'd'occasione'. In altre parole, è nel momento specifico in cui una determinata informazione mi serve che mi metto a cercarla, e la mia ricerca richiede che io compia ogni volta e in prima persona un certo numero di azioni, alcune delle quali senz'altro ripetitive: ad esempio collegarmi alla pagina di HotBot, di Altavista o di Yahoo!, impostare i parametri della ricerca, restare collegato mentre ne aspetto i risultati. Sarebbe molto comodo, in questi casi, disporre di un 'segretario' che conosca più o meno i miei interessi, sappia prevedere e anticipare le mie richieste, compia al posto mio (prendendo autonomamente le decisioni più opportune) le azioni più ripetitive, e magari anche qualcuna di quelle meno ripetitive. L'idea di agente software cerca di avvicinarsi a questo ideale07: in sostanza, si tratta di incaricare un programma di svolgere per mio conto, anche a intervalli prefissati, determinate ricerche, magari chiedendogli di reagire autonomamente ai risultati della ricerca stessa (ad esempio 'filtrandoli' attraverso l'uso di criteri che potrebbero essere difficili o impossibili da impostare direttamente sul motore di ricerca utilizzato). Se il programma 'agente' non è poi fisicamente legato al mio computer (potrebbe ad esempio trattarsi di un programma ospitato da un server remoto, o addirittura 'distribuito' fra più server remoti), potrei affidargli ricerche e compiti da svolgere anche mentre il mio computer è scollegato dalla rete, e il contascatti della mia utenza telefonica resta tranquillo. Per certi versi, alcuni degli strumenti che abbiamo visto fin qui possiedono già un limitato sottoinsieme di queste caratteristiche. Quello che manca, nella maggior parte dei casi, è però la capacità di prendere decisioni realmente autonome, reagendo dinamicamente alle caratteristiche dell'universo informativo nel quale si muovono. Occorre dire che di programmi di questo genere per ora esistono ben pochi esempi. Uno dei pochi che si avvicinano a soddisfare almeno alcuni dei requisiti sopra delineati è Copernic Agent (http://www.copernic.com/), arrivato al momento in cui scriviamo alla versione 6. Copernic esiste in tre versioni: Basic (gratuita), Personal (costa circa 30 euro) e Professional (circa 80 euro). La versione migliore è ovviamente la Professional, che consente fra l'altro di programmare ed eseguire con regolarità, in maniera automatica, le ricerche selezionate. Copernic è in grado di effettuare ricerche complesse su un vasto spettro di motori di ricerca e fonti informative, incluse, ad esempio, alcune fra le maggiori librerie in rete. Nel complesso gli strumenti di ricerca che il programma è in grado di interrogare per noi, integrandone i risultati, sono oltre mille, suddivisi in centoventi categorie relative sia all'argomento sia all'area geografica della ricerca. Per fare qualche esempio, la versione Professional di Copernic è in grado di svolgere automaticamente e in maniera programmata ricerche su un insieme di fonti giornalistiche italiane in rete (nel momento in cui scriviamo il programma ne utilizza sette, fra le quali i siti di Corriere della Sera, Repubblica, L'Unità, CNN.it e le notizie sull'Italia di Yahoo! News), trasformandosi in uno strumento prezioso per la realizzazione di una sorta di piccola rassegna stampa quotidiana su argomenti o persone di nostro interesse. Può svolgere ricerche su testate e siti specializzati, per trovare ad esempio recensioni di un certo film o di un certo disco, o una ricetta di cucina, o i testi di una determinata canzone. Può avvertirci delle nuove pagine inserite in rete che soddisfino determinati criteri di ricerca, svolgendo la stessa ricerca più volte a scadenze prefissate (ad esempio ogni giorno, o ogni settimana) e informandoci solo delle pagine aggiunte o modificate rispetto alla ricerca precedente. Può svolgere ricerche specifiche su immagini, video e audio. Insomma, una collezione di strumenti di tutto rispetto. Il programma si integra anche piuttosto bene in Internet Explorer, aggiungendovi una barra degli strumenti che offre funzioni simili a quelle della toolbar di Google (ad esempio la possibilità di evidenziare nella pagina le parole cercate), assieme a un campo per la selezione e il lancio delle metaricerche. Un programma dalle caratteristiche in parte simili a quelle di Copernic è BullsEye, della Intelliseek (http://www.intelliseek.com/). Al momento in cui scriviamo, la versione professionale del programma - la più completa - costa 199 dollari. Fino a un paio di anni fa Copernic esisteva sia per Windows sia per Macintosh, ma le ultime versioni sono destinate solo ai computer che usano il sistema operativo di casa Microsoft. Gli utenti Apple, però, non possono lamentarsi troppo: del loro sistema operativo fa infatti parte una componente che, se non è ancora un vero e proprio agente di ricerca, ne offre tuttavia alcune caratteristiche. Ci riferiamo ovviamente a Sherlock, compreso nel MacOS a partire dalla versione 8.5 e ulteriormente potenziato in Mac OSX. Già nella sua versione nativa Sherlock è in grado di svolgere operazioni assai sofisticate (per fare un solo esempio, può seguire per noi le fasi di una spedizione attraverso corriere internazionale). Inoltre, è possibile potenziarne le funzionalità attraverso appositi plug-in. Ne esistono moltissimi, un elenco è disponibile nella relativa pagina di TuCows all'indirizzo http://mac.tucows.com/general_sherlock-plug_default.html. Il numero dei programmi e degli strumenti che possono essere fatti rientrare, con criteri abbastanza larghi, nella classe degli agenti di ricerca è ovviamente assai più vasto delle poche segnalazioni che abbiamo incluso in questa sezione. Chi volesse conoscerne altri troverà un buon punto di partenza nella sezione 'Searchbots' di TuCows relativa al proprio sistema operativo, o in siti specializzati come BotSpot (http://www.botspot.com/), BotKnowledge (http://www.botknowledge.com/) o Agentland (http://www.agentland.com/). Attenzione però ad evitare agenti software troppo invadenti, come il diffuso BonziBuddy (http://www.bonzi.com/bonzibuddy/bonzibuddyfreehom.asp): uno scimmione animato dall'apparenza divertente, capace di parlare con voi, suonare, raccontare barzellette, svolgere ricerche (in maniera in verità tutt'altro che intelligente), gestire la vostra posta elettronica, e soprattutto... sommergervi di pubblicità. Va detto in conclusione che il settore destinato probabilmente alla maggiore espansione è quello dei cosiddetti 'web-based searchbots', ovvero degli agenti che, anziché risiedere sul nostro computer, sono ospitati da server esterni e vengono utilizzati via web. Una volta impostata una ricerca, questo tipo di agenti può svolgerla autonomamente, sfruttando ad esempio la posta elettronica per 'restare in contatto' con noi ed informarci nel tempo sulle proprie attività e sui risultati trovati. Qualche esempio - ancora piuttosto limitato - esiste già. Uno dei primi è stato Tracerlock (http://www.tracerlock.com/), che offre per 4 dollari al mese un servizio di monitoraggio nel tempo dei principali motori di ricerca, informandoci via mail quando sono disponibili nuove pagine web che rispondono ai criteri indicati È prevedibile che il settore degli agenti di ricerca intelligenti conoscerà nei prossimi anni un'evoluzione tale da far sembrare questi primi strumenti solo rozze e primitive approssimazioni ad applicazioni assai più sofisticate, potenti e autonome. Per adesso, ci limitiamo a segnalare una prospettiva, una probabile linea di tendenza. Note
|
 |
|||||||||
|
|
|
|||||||||
 |
 |
 |
|||||||||
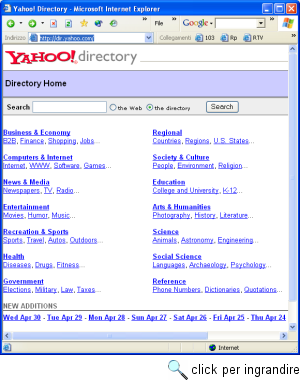
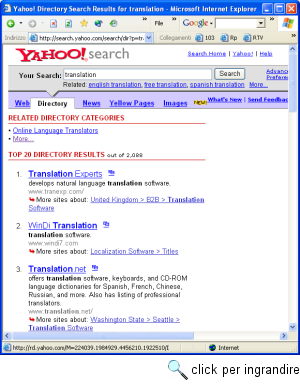
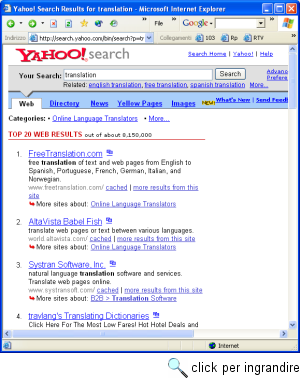
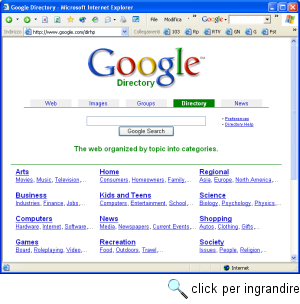
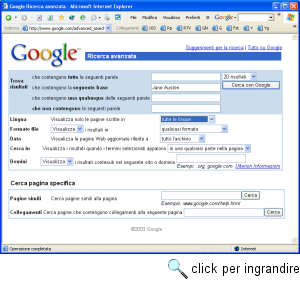
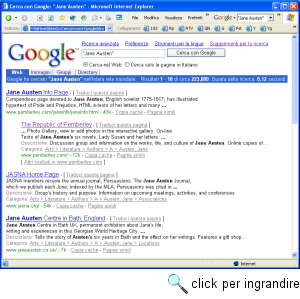
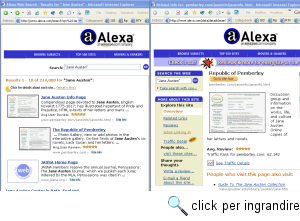



| Inizio pagina |  |
 |